블로그 검색 기능 개발 과정
블로그를 만든 지 거의 2년이 다 되어가고 작성한 포스트도 어느덧 20개를 넘었다. 콘텐츠가 쌓이니 자연스럽게 ‘검색’ 기능을 붙이고 싶은 욕심이 들었다. Gatsby를 사용해서 만든 블로그라서 플러그인을 검색해 보니 역시 검색 기능을 구현한 것이 있었다. 자바스크립트 기반의 검색 엔진인 Elasticlunr.js를 사용한 플러그인이었는데, 테스트해 보니 안타깝게도 한글 문장은 인덱싱되지 않았다. 그래서 공부도 할 겸 직접 구현하기로 했다.
자체 검색 엔진 구현
우선 검색 기능에 대한 요구 사항을 정리해 보았다.
- Github pages에 호스팅 된 정적인(static) 사이트라서 검색은 브라우저에서 진행되어야 한다.
- 클라이언트 사이드 검색이므로 인덱싱 파일은 크기가 가능한 한 작아야 한다.
- 영어 및 한글도 검색 가능해야 한다.
- 검색 결과에는 매칭된 포스트 제목과 태그를 표시해야 한다.
node.js에서 검색을 위한 콘텐츠 인덱싱 진행
콘텐츠를 단어를 추출한 후 단어와 그 단어를 포함한 페이지를 매칭시킨 역색인을 구성하는 방법을 사용했다. 처음에는 문장 검색을 위해 글자를 하나하나 분리하고 인접한 단어 정보를 저장해서 검색 결과와 함께 문장을 다시 구성할 수 있도록 하려고 했었다. 그런데 그 과정에서 인덱싱 파일의 크기가 너무 커져 버렸고 효율도 좋지 않았다. 결국, 단어 단위의 역 인덱스로 내가 할 수 있는 구현을 하자는 쪽으로 방향을 틀었다.
인덱싱 데이터 구성은 node.js 환경에서 아래의 과정을 통해 진행된다.
- 콘텐츠가 포함된 모든 마크다운(md) 파일을 가져온다.
- 마크다운에서 YAML 형식으로 작성된 front matter 영역과 본문을 분리한다.
- remark 라이브러리로 콘텐츠 본문을 텍스트로 변환한다.
- 본문 텍스트에서 단어를 분리하고 포스트 경로로 매핑하는 단어 맵을 만든다.
- front matter에서는 제목, 태그 정보를 추출한다.
- 검색에 필요한 데이터를 JSON 파일로 저장한다.
인덱싱 파일을 생성하면 아래과 같은 형태가 된다.
{
"wordList": [
"[번역]",
"자바스크립트",
"피로감을",
...
],
"wordMap": {
"@_[번역]": { "r": [1, 4, 5, 9, 10, 11, 15, 18, 20, 24, 26] },
"@_자바스크립트": { "r": [1, 2, 4, 8, 15, 18, 20, 24, 26, 27] },
"@_피로감을": { "r": [1] },
...
},
"routeMap": {
"1": {
"route": "/posts/2016-12-19-A-Study-Plan-To-Cure-JavaScript-Fatigue",
"title": "[번역] 자바스크립트 피로감을 줄여주기 위한 학습 계획",
"tags": ["번역", "JavaScript", "React", "Redux", "Gatsby", "ES"]
},
...
},
"tagList": [
"번역",
"JavaScript",
"React",
...
]
}사용자의 검색어를 입력받으면 wordList와 tagList에서 매칭되는 단어를 찾은 후 routeMap에 저장된 정보를 활용해서 결과를 보여주는 방식이다. 실제 검색 로직에서는 결과 정렬을 위한 랭킹 점수 부여 등의 과정이 추가된다.
콘텐츠의 총글자 수가 약 35만 자인 상태에서 인덱싱 파일을 생성하니 그 크기가 350KB 정도로 브라우저에서 충분히 감당할 수 있을 정도였다. gzip으로 인코딩하면 100KB까지 줄어든다. 하지만 그 크기는 점점 커질 테니, 인덱싱 데이터를 서비스 워커를 사용해서 미리 불러오도록 했다.
서비스 워커(Service Worker)를 사용한 검색 데이터 캐싱
서비스 워커는 브라우저의 백그라운드에서 동작하면서 웹앱과 브라우저, 네트워크 사이의 프락시 역할을 한다. 원격 데이터를 호출하는 fetch 이벤트를 감지해서 특정 네트워크 요청에 대한 응답을 캐싱하는 등의 작업이 가능하다. 그리고 웹앱에 필요한 리소스를 내려받아서 CacheStorage에 저장해서 재방문 시 빠르게 가져올 수 있도록 한다. (서비스 워커를 사용하면 백그라운드 동기화도 가능하지만 아직은 크롬 브라우저에서만 가능한 기술이다) 이를 바탕으로 네트워크가 불안하거나 오프라인인 상태에서도 앱이 구동할 수 있도록 할 수 있다. 네트워크 요청을 하지 않는 앱이라면 네이티브 앱과 다를 바가 없게 되는 것이다.
검색 기능을 구현하면서 서비스 워커를 사용해서 덩치가 큰 인덱싱 파일을 CacheStorage에 저장했다. 이런 기능을 간편히 사용하기 위한 라이브러리에는 sw-precache가 있다. Gatsby에는 이를 바탕으로 한 플러그인이 이미 존재하고 있으며, 나도 사용하고 있었다. gatsby-plugin-offline이 그것인데, 기본 옵션만 사용해도 웹사이트 데이터를 잘 캐싱해준다. 이 플러그인의 추가 옵션을 살짝 수정해서 덩치가 큰 인덱싱 파일도 저장하도록 했다.
const rootDir = 'public'
...
{
resolve: 'gatsby-plugin-offline',
options: {
staticFileGlobs: [
`${rootDir}/search/*.json`, // 검색 인덱싱 파일 추가
`${rootDir}/**/*.{woff2}`,
`${rootDir}/commons-*js`,
`${rootDir}/app-*js`,
`${rootDir}/index.html`,
`${rootDir}/manifest.json`,
`${rootDir}/manifest.webmanifest`,
`${rootDir}/offline-plugin-app-shell-fallback/index.html`,
],
},
},
...
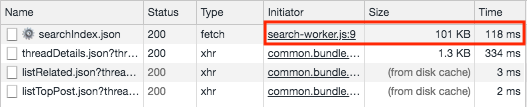 최초 방문
최초 방문
 재방문
재방문
스크린 샷을 살펴보면 searchIndex.json 파일을 가져오는 데 걸리는 시간이 처음에는 118ms지만 재방문했을 때는 서비스 워커를 통해 10ms가 걸렸다. 1/10 정도로 많이 줄어들었다는 사실을 확인할 수 있다.
웹 워커(Web Worker)를 사용한 검색
자바스크립트는 싱글 스레드라고 알고 있는 사람들이 많지만, 웹 워커(Web Workers)를 사용하면 멀티 스레드 프로그래밍이 가능하다. 그리고 서비스 워커보다는 브라우저 지원 폭이 넓어서 인터넷 익스플로러 9를 반드시 지원해야 하는 웹사이트가 아니라면 사용해도 된다. 웹 워커를 사용하면 좋은 사례에는 다음과 같은 것들이 있다.
- Ray tracing(이미지 렌더링 기술)
- 암호화
- 데이터 prefetching
- Progressive Web App
- 문법 검사
- 타이머
상대적으로 큰 데이터를 처리해야 해서 검색 로직 구현에도 웹 워커를 사용하기로 했다. 하지만 웹 워커와 메인 스레드 사이의 통신을 위해서는 postMessage를 사용해서 데이터를 보내고, onmessage 이벤트 핸들러에서 데이터를 받아서 처리해야 한다. 워커에 의미 있는 이름을 가진 메소드를 추가해서 보다 가독성 있는 방법으로 통신할 방법은 아직은 없다. 이를 개선하기 위한 comlink라는 라이브러리가 있긴 하다. 하지만 나는 redux에서 하는 것처럼 정형화된 데이터를 주고받는 방식으로 구현했다.
// 메인 스레드 소스 코드
let searchWorker
if (window.Worker && !searchWorker) {
// 웹 워커 등록
searchWorker = new Worker('/js/search-worker.js')
}
const searchService = {
// 검색
find: (searchInput = '') => {
searchWorker.postMessage({
action: 'SEARCH_REQUEST',
payload: {
searchInput,
},
})
},
}// 웹 워커 소스 코드
onmessage = function(e) {
var action = e.data.action
var payload = e.data.payload
switch (action) {
case 'SEARCH_REQUEST':
search(payload.searchInput)
break
default:
break
}
}
function search(input) {
...
}이런 식으로 스레드 간에 데이터를 주고받을 수 있다. 위의 코드에서는 메인 스레드에서 메시지를 보내고, 웹 워커에서 메시지를 받는 과정이 표현되어 있지만 당연히 반대로도 가능하다.
웹 워커를 사용해서 350KB 크기의 데이터를 검색하는 데 보통 0.15~0.2초가 걸렸다.
Node.js, 브라우저, 웹 워커에서 함께 사용할 모듈 작성
검색 기능을 구현하는 과정에서 node.js, 브라우저, 웹 워커에서 공통으로 사용해야 하는 로직이 발견되었다. 인덱싱과 검색 과정에서 문장과 단어의 불필요한 문자를 제거하는 기능이 대표적이다. 그리고 웹 워커를 사용하니 스레드 간의 메시지를 구분할 때 사용하는 enum 역할을 하는 문자열도 일치시킬 필요가 생겼다.
하지만 세 환경에서는 모듈을 사용하는 방식이 서로 다르다. node.js에서는 모듈을 사용하기 위해 자체 모듈인 module, require를 사용하지만, 브라우저와 웹 워커에서는 사용할 수 없다. 브라우저에서는 Webpack과 ES6의 export, import를 사용한다. 그리고 웹 워커에서는 importScripts 함수를 통해 외부 스크립트 내부에서 할당한 전역 객체를 사용해야 한다.
이 3가지 환경에서 모두 사용할 수 있는 모듈 선언 방식이 UMD (Universal Module Definition) 패턴이다. 링크된 Github 저장소의 templates 폴더에는 여러 사례에 대한 예제 코드가 작성되어 있다. 검색 엔진을 위한 모듈 작성에는 returnExports.js 예제를 활용했다.
// searchUtil.js
// 즉시 실행 함수(IIFE) 형태로 선언한다. factory는 모듈 객체를 반환하는 함수다.
;(function(root, factory) {
// webpack을 위한 AMD 모듈 선언 방식,
// webpack은 AMD, CommonJS 방식 둘 다 지원한다.
if (typeof define === 'function' && define.amd) {
define(null, factory)
// node.js에 해당하는 케이스
} else if (typeof module === 'object' && module.exports) {
module.exports = factory()
// 모듈 객체를 전역 컨텍스트에 할당. 웹 워커와 브라우저에서 사용할 수 있다.
} else {
root.searchUtil = factory()
}
})(this, function() {
// 모듈 객체
return {
actions: {
SEARCH_REQUEST: 'SEARCH_REQUEST',
},
trimText: function(str) {
...
},
}
})이렇게 선언된 모듈은 각각의 환경에 맞는 방식으로 불러와서 사용할 수 있다.
// node.js에서 사용
const { actions } = require('../static/js/searchUtil')// ES6 모듈에서 사용
import { actions } from '../static/js/searchUtil'// 웹 워커에서 사용
importScripts('./searchUtil.js')
console.log(searchUtil.actions.SEARCH_REQUEST)향후 개선 방향
검색 기능을 구현하긴 했지만 말 그대로 동작할 정도로만 만들어 두었을 뿐이다. 검색어가 입력되면 단어 목록 전체를 살펴보기 때문에 현재 O(n)의 검색 시간이 걸리는 상태다. 이를 개선하기 위해서는 당장 생각하는 방법으로는 단어를 초성이나 글자별로 그룹화해서 일부만 찾아보는 방식이 있겠다. 검색 결과 캐싱, 랭킹 부여 방식도 개선 등 고칠 점이 많으니 천천히 시도해 볼 생각이다.