자바스크립트 정규표현식의 capturing group
capturing group, non-capturing group, 그리고 lookahead
정규표현식
정규표현식은 문자열을 표현할 수 있는 패턴이다. 이메일, 전화번호 등의 유효성을 검증하거나, 문자열에서 원하는 부분을 추출하기 위한 용도로 사용된다. 예를 a로 시작하는 영어 단어의 패턴은 아래와 같다.
/^a[a-z]*$/i정규표현식은 자바스크립트 객체이며 test, exec 등 정규표현식을 활용하기 위한 여러 가지 메소드를 가지고 있다. 객체(Object)를 new 키워드 없이 중괄호({}, brace)만으로 선언 가능한 것처럼, 정규표현식도 위에서 제시한 것처럼 슬래쉬(/) 사이에 패턴을 입력하는 것으로 만들 수도 있고 new 키워드를 사용해서 만들 수도 있다.
const startWithA = new Regexp('^a[a-z]*$', 'i')정규표현식은 특수한 의미가 있는 기호들을 잘 활용해야 한다. 사실 그게 전부라고도 할 수 있다. 하지만 그런 기호들은 실제 의미와 어떠한 관계도 없어 보이는 것들이 대부분이라 정규표현식을 처음 접하면 그저 이해할 수 없는 암호처럼 보이곤 한다. 계속 사용하면서 익숙해지거나 외우는 수밖에 없는 부분이다.
캡쳐링 그룹(capturing group)
정규표현식에서 캡쳐링 그룹은 괄호로 둘러싼 영역이다. 캡쳐링 그룹이 있으나 없으나 패턴의 유효성을 검증하는 test 메소드의 결과는 같다. 하지만 문자열(String) 객체가 가지고 있는 match 메소드의 결과는 달라진다. 예를 들어 ‘github.com’ 사이트가 복수의 서브도메인을 가진다고 할 때, 서브도메인을 포함한 주소를 표현하는 패턴은 다음과 같다.
var url = 'https://rhostem.github.com'
var domain = /https?:\/\/\w+\.github.com/
url.search(domain) // 0
url.match(domain) // ["https://rhostem.github.com", index: 0, ...]서브도메인 영역을 괄호로 둘러싸서 캡쳐링 그룹을 만들면, match 메소드의 결과는 달라진다.
var url = 'https://rhostem.github.com'
var domain = /https?:\/\/(\w+)\.github.com/
url.search(domain) // 0
url.match(domain) // ["https://rhostem.github.com", "rhostem", index: 0, ...]search 메소드는 문자열 내부에서 정규표현식이 매칭이 시작되는 지점을 반환한다. 위의 예제에서는 문자열 처음부터 매칭되기 때문에 결과가 0이다.
match 메소드의 결과 배열에서 첫 번째 항목은 전체 매칭 문자열이며, 두 번째부터는 캡쳐링 그룹 안에 있는 문자열이 차례대로 들어간다. 캡쳐링 그룹을 사용하면 패턴 안의 원하는 부분을 보다 편리하게 분리해낼 수 있다.
그리고 String 객체의 replace 메소드도 정규표현식을 활용하는데, 캡쳐링 그룹을 사용하면 패턴 확인과 함께 원하는 부분만 교체하는 기능을 구현할 수 있다. 위의 정규표현식을 조금 수정해서 서브도메인 영역을 www문자열로 바꿔보자.
'rhostem.github.com'.replace(/^\w+(\.github\.com)$/, 'www$1')
// www.github.com서브도메인 영역을 제외한 부분을 캡쳐링 그룹으로 둘러쌌고, replace 메소드의 두번째 인자에는 대체할 문자열을 패턴을 전달했다. 여기서 $1은 첫 번째 캡쳐링 그룹으로 둘러싼 영역에해당한다. 만약 두 번째 캡쳐링 그룹이 있다면 해당 문자열은 $2가 될 것이다. 자세한 사항은 링크를 참조하기 바란다.
코드 에디터에서의 정규표현식과 캡쳐링 그룹의 활용
코드 에디터에서 검색을 할 때 정규표현식을 지원하는 경우가 많다. 그리고 캡쳐링 그룹과 $1같은 파라미터 문자열도 지원한다. 이를 사용하면 여러 파일을 한꺼번에 쉽게 수정하는 것이 가능하다.
예를 들어 styled-components 라이브러리를 사용하고 있는데, v3에서 v4로 업그레이드하려고 할 때 모듈 사용 방법이 달라져서 수정할 사항이 많이 생긴다. 대표적으로 extend 메소드의 사용방식이 달라진다.
// v3
const ExtendedComponent = Component.extend`
color: green;
`
// v4
const ExtendedComponent = styled(Component)`
color: green;
`extend 메소드를 많이 사용했다면 하나하나 고치는데 제법 많은 시간이 걸릴 것이다. 이럴 때 정규표현식과 Visual Studio Code의 ‘파일에서 바꾸기’ 기능을 사용하면 한 번에 모두 바꿀 수 있다.
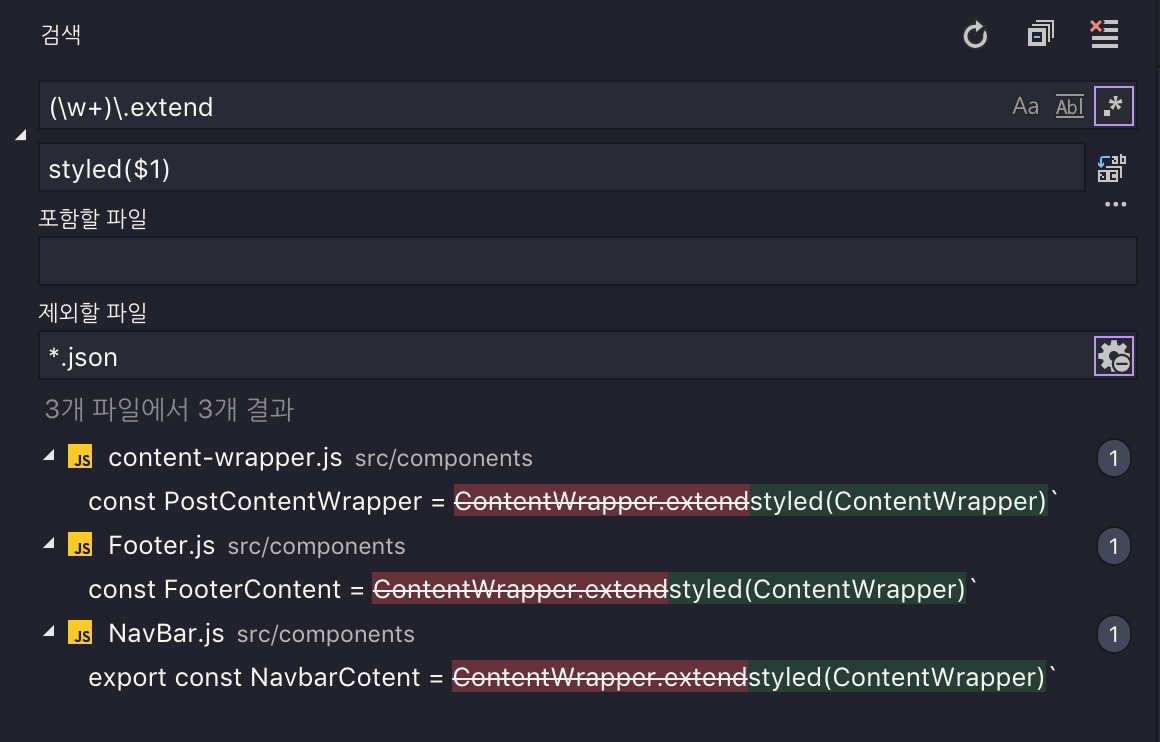
이처럼 정규표현식은 에디터에서도 검색과 수정에 유용하게 활용할 수 있다.
논-캡쳐링 그룹(non-capturing group)
그룹 시작 부분에 ?: 기호를 추가하면 non-capturing 그룹이 된다. 캡쳐링 그룹이 결과 배열에 추가되는 것과는 달리 non-capturing 그룹은 결과 배열에 추가되지 않는다. 아래는 두 개의 캡쳐링 그룹을 사용해서 단어의 위치를 변경하는 예제다.
'javascript'.replace(/(java)(script)/, `$2-$1`) // script-javajava와 script를 캡쳐링 그룹으로 지정했기에 패턴을 사용해서 위치를 바꿀 수 있었다. 하지만 캡쳐링 그룹의 시작 부분에 ?:을 추가하면 non-capturing 그룹이 되어 결과 배열에 추가되지 않으며, 결과적으로 $2에 해당하는 패턴을 찾을 수 없어 다른 결과가 나온다.
'javascript'.replace(/(java)(?:script)/, `$2-$1`) // "$2-java"그럼 이런 생각이 들 것이다. 저건 결국 괄호로 둘러싸지 않은 것과 같은데, 왜 굳이 non-capturing 그룹이라는 패턴을 지원할까? 라고 말이다. non-capturing 문법이 있는 이유는 그룹이 다른 역할로도 사용되기 때문이다. 예를 들어 앞서 서브도메인을 추출한 예제에서, http 프로토콜이 포함된 것과 포함되지 않은 문자열을 모두 매칭시키면서 서브도메인만 캡쳐링 그룹에 포함하고 싶을 때가 있을 것이다. 그러면 아래와 같이 작성할 수 있다.
/(?:https?:\/\/)?(\w+)\.github.com/.exec('rhostem.github.com')
// ["rhostem.github.com", "rhostem", index: 0, ...]/(?:https?:\/\/)?(\w+)\.github.com/.exec('https://rhostem.github.com')
// ["https://rhostem.github.com", "rhostem", index: 0, ...]http 프로토콜 패턴 부분을 그룹으로 만들고, 바로 다음에 조건부 매칭을 의미하는 ? 기호를 붙여서 프로토콜에 해당하는 문자열 전체가 조건부 패턴이 되었다. 하지만 매칭 결과 배열에는 포함하고 싶지 않기 때문에 ?: 기호를 사용해서 non-capturing 그룹으로 지정했다. non-capturing 그룹을 사용하지 않았다면 아래처럼 프로토콜 영역도 결과에 포함된다.
["https://rhostem.github.com", "https://", "rhostem", index: 0, ...]non-capturing 그룹 덕분에 항상 결과 배열의 2번째 아이템이 서브도메인이 될 것이므로, 다음과 같은 함수를 작성해서 서브도메인을 추출할 수 있게 된다.
const getSubDomain = (url = '') => {
const matches = /(?:https?:\/\/)?(\w+)\.github.com/.exec(url)
return matches && matches[1] // 첫 번째 캡쳐링 그룹
}Lookahead
Lookahead도 그룹 패턴으로, Lookahead 그룹 안에 있는 패턴이 뒤에 올 때만 매칭이 된다. 캡쳐링 그룹과 다른 점은 전체 매칭 결과에 Lookahead 그룹 안에 있는 패턴이 포함되지 않는다는 것이다. lookahead(앞쪽을 보다)라는 이름이 가지는 의미 그대로 관찰자 역할을 할 뿐 전체 패턴에서는 제외되어 있다고 여기면 될 것 같다
// capturing group
/java(script)/.exec('javascript') // ["javascript", "script", index: 0, ...]// positive lookahead
/java(?=script)/.exec('javascript') // ["java", index: 0, ...]Lookahead에는 positive와 negative가 있는데, 앞서 제시한 ?= 기호는 positive lookahead로서 그룹 안의 패턴이 뒤에 와야 함을 의미하며, negative lookahead를 나타내는 ?! 기호는 그룹 안의 패턴이 뒤에 오지 말아야 함을 의미한다. Negative lookahead 패턴을 사용한 아래의 정규표현식을 사용하면 ‘java’ 뒤에 ‘script’라는 문자열이 오지 않는 모든 문자열을 매칭시킬 수 있다
/java(?!script)/.exec('java coffee') // ["java", index: 0, ... ]Lookbehind
Lookahead와 정반대의 역할을 하며 그룹 안의 패턴이 앞에 나올 때 매칭이 된다. 하지만 ECMAScript 2018 스펙이라서 글을 쓰는 시점에서는 Chrome 브라우저에서만 사용 가능하며 Safari, FireFox는 브라우저는 지원하지 않는 문법이다.
Lookbehind도 positive, negative가 있으며, positive lookbehind는 ?<=, negative lookbehind는 ?<! 기호로 표현한다.
// java 다음에 script가 와야 한다.
/(?<=java)script/.exec('javascript') // ["script", index: 6, ...]// java가 아닌 문자열 다음에 script가 와야 한다.
/(?<!java)script/.exec('purescript') // ["script", index: 4, ...]